Noam Razin
Assistant Professor
Computer Science & AI Department, Bar-Ilan University
razinno [at] cs.biu.ac.ilI am an Assistant Professor in the Computer Science & AI Department at Bar-Ilan University. My research focuses on the fundamentals of deep learning and modern artificial intelligence (AI) systems. By combining mathematical analysis with systematic experimentation, I aim to develop theories that shed light on how modern AI works, identify potential failures, and yield principled methods for improving efficiency, reliability, and performance.
Previously, I was a postdoctoral fellow at Princeton University, hosted by Sanjeev Arora. Before that, I obtained my PhD in Computer Science at Tel Aviv University under the supervision of Nadav Cohen.
I am recruiting MSc and PhD students. Please see the note below if you are interested in working with me.
Recent Research
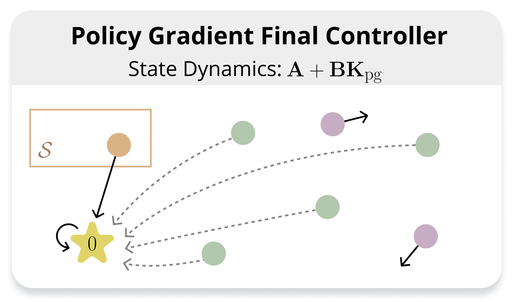
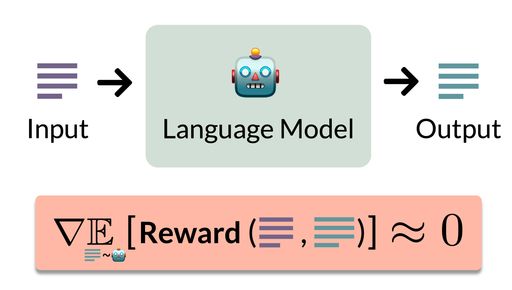
Recently, I have been working on aspects of converting language models to useful AI systems (aka post-training), including failures of preference-based alignment [1] and policy gradient methods [2], what makes a good proxy reward function [3, 4], catastrophic forgetting [5], and reward model generalization [6].
News
Joined the Computer Science & AI Department at Bar-Ilan University as an Assistant Professor.
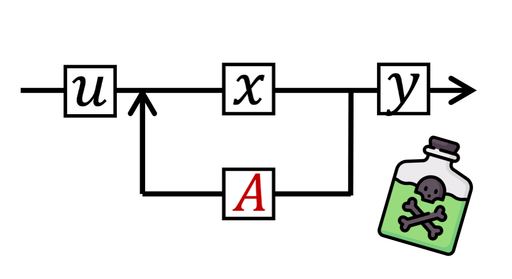
Our work on data poisoning for structured state space models has won the Israel AI Safety Research Prize. Congrats to Yonatan Slutzky and Yotam Alexander, who led the project!
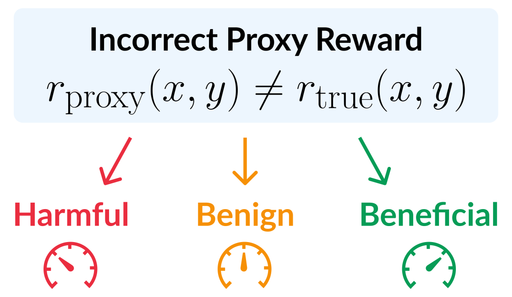
New paper categorizes imperfect proxy rewards according to their effect on policy gradient optimization. It highlights that, although incorrect rewards are conventionally viewed as harmful, they can also be benign or even beneficial!
Why is Your Language Model a Poor Implicit Reward Model? received a best paper runner-up award at the NeurIPS 2025 Reliable Machine Learning from Unreliable Data Workshop and was accepted to ICLR 2026!
Publications
See also Google Scholar* indicates equal contribution

Selected Talks
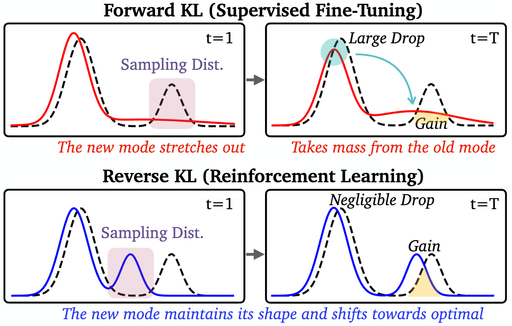
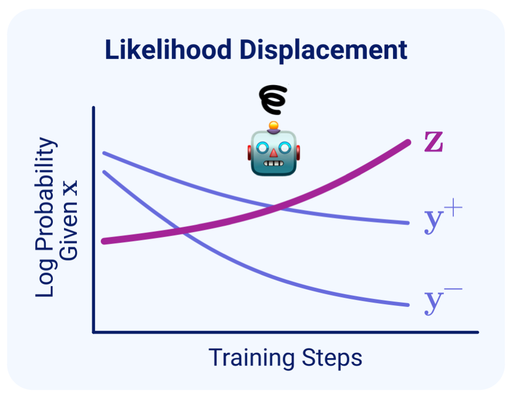
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Deep Learning: Classics and Trends Seminar · Jan 2025
Teaching
Current
Theoretical Foundations of Deep Learning
Lecturer · Bar-Ilan University · 2026–
Past
Fundamentals of Deep Learning
Guest Lecturer · Princeton University · 2025
Introduction to Reinforcement Learning
Guest Lecturer · Princeton University · 2025
First Steps in Research Honors Seminar
Guest Lecturer · Tel Aviv University · 2021–2024
Foundations of Deep Learning
Teaching Assistant · Tel Aviv University · 2021–2023