Noam Razin
Postdoctoral Fellow
Princeton Language and Intelligence, Princeton University
📢 I am on the academic and industry job market for 2025/26
I am a Postdoctoral Fellow at Princeton Language and Intelligence, Princeton University. My research focuses on the fundamentals of artificial intelligence (AI). By combining mathematical analyses with systematic experimentation, I aim to develop theories that shed light on how modern AI works, identify potential failures, and yield principled methods for improving efficiency, reliability, and performance. Most recently, I have been working on language model alignment, including reinforcement learning and preference optimization approaches.
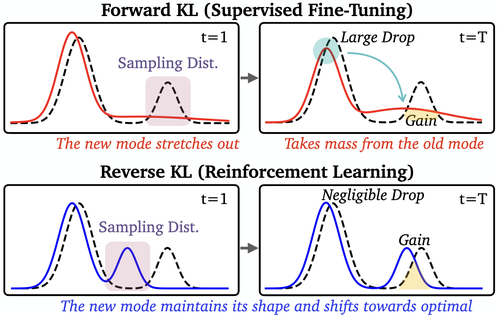
- In [1], we identify a connection between reward variance and the flatness of the reinforcement learning objective landscape. Building on this, [2] provides an optimization perspective on what makes a good reward model for RLHF, establishing that more accurate reward models are not necessarily better.
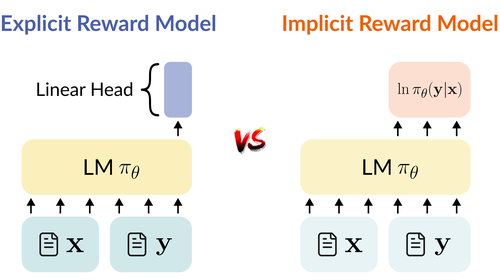
- In [3], we investigate why language models are often poor implicit reward models, and show that they tend to rely on superficial token-level cues.
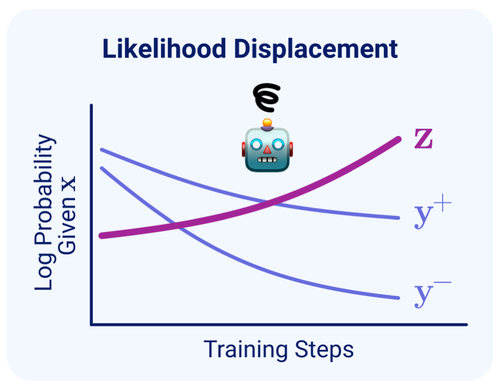
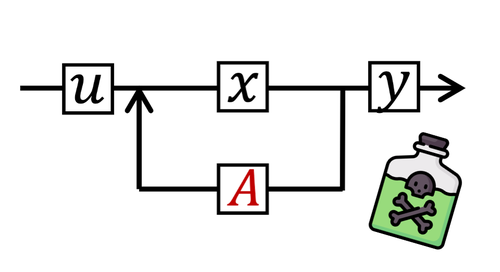
- In [4], we characterize the causes for likelihood displacement — the counter-intuitive phenomenon where preference optimization decreases the probability of preferred responses (instead of increasing it as intended). We demonstrate that likelihood displacement can cause surprising failures in alignment and give preventative guidelines.
My work is supported in part by a Zuckerman Postdoctoral Scholarship. Previously, I obtained my PhD in Computer Science at Tel Aviv University, where I was fortunate to be advised by Nadav Cohen. During my PhD, I interned at Apple Machine Learning Research and Microsoft Recommendations Team, and received the Apple Scholars in AI/ML and Tel Aviv University Center for AI & Data Science fellowships.