Noam Razin
Noam Razin
News
Publications
Talks
Blog Posts
Teaching
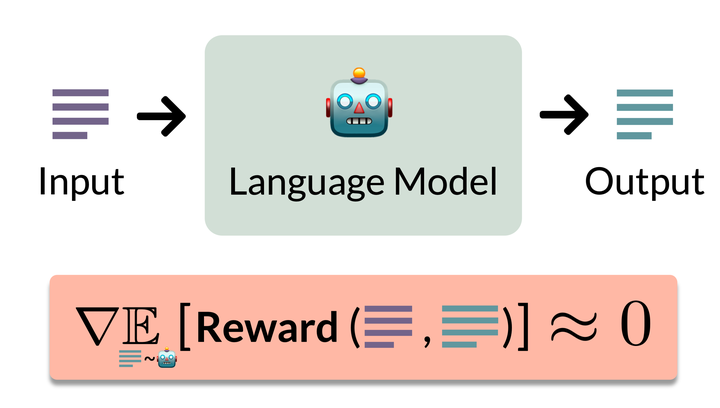
Vanishing Gradients in Reinforcement Finetuning of Language Models
Noam Razin
,
Hattie Zhou
,
Omid Saremi
,
Vimal Thilak
,
Arwen Bradley
,
Preetum Nakkiran
,
Joshua Susskind
,
Etai Littwin
January 2024
PDF
Cite
Code
Poster
Type
Conference paper
Publication
International Conference on Learning Representations (ICLR), 2024
Vanishing Gradients
Policy Gradient
Reinforcement Finetuning
Language Models
Related
What Algorithms Can Transformers Learn? A Study in Length Generalization
Cite
×