Noam Razin
Noam Razin
News
Publications
Talks
Blog Posts
Teaching
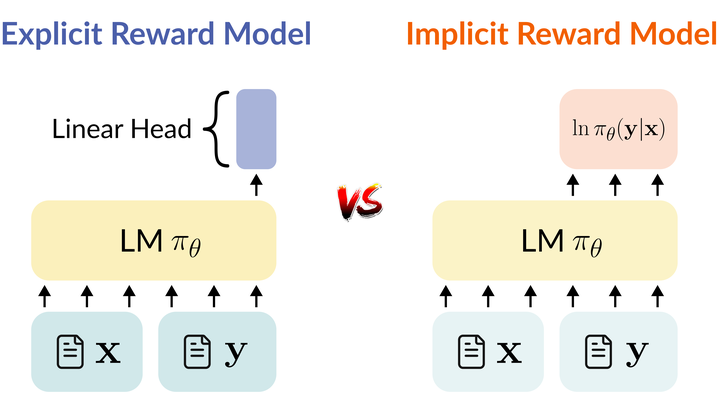
Why is Your Language Model a Poor Implicit Reward Model?
Noam Razin
,
Yong Lin
,
Jiarui Yao
,
Sanjeev Arora
July 2025
PDF
Cite
Code
Poster
Type
Preprint
Publication
arXiv:2507.07981, 2025
Reward Models
Language Models
Reinforcement Learning from Human Feedback
Out-of-Distribution Generalization
Related
What Makes a Reward Model a Good Teacher? An Optimization Perspective
Unintentional Unalignment: Likelihood Displacement in Direct Preference Optimization
Implicit Bias of Policy Gradient in Linear Quadratic Control: Extrapolation to Unseen Initial States
Vanishing Gradients in Reinforcement Finetuning of Language Models
What Algorithms Can Transformers Learn? A Study in Length Generalization
Cite
×